ељУйАЯеЇ¶жИРдЄЇзЂЮдЇЙеКЫпЉМжХ∞жНЃе∞±жШѓжЬАиѓЪеЃЮзЪДи£БеИ§гАВжЬђжЦЗдї•вАЬжХ∞жНЃеИЖжЮРпЉЪTESзЪДйАЯеЇ¶и°®зО∞вАЭдЄЇдЄїйҐШпЉМеЄ¶дљ†дїОйЗЗж†ЈгАБжЄЕжіЧгАБеїЇж®°еИ∞жіЮеѓЯпЉМйАРе±ВжП≠еЉАTESеЬ®дЄНеРМдЄЪеК°еЬЇжЩѓдЄ≠зЪДйАЯеЇ¶йЭҐи≤МгАВй¶ЦеЕИиѓіжШОжИСдїђзЪДжХ∞жНЃжЭ•жЇРпЉЪи¶ЖзЫЦзЇњдЄКзЬЯеЃЮиѓЈж±ВзЪДжЧ•ењЧгАБеРИжИРеОЛжµЛжХ∞жНЃдї•еПКзђђдЄЙжЦєзЫСжµЛзВєпЉМжЧґйЧіиЈ®еЇ¶и¶ЖзЫЦињСдЄЙдЄ™жЬИзЪДйЂШе≥∞дЄОйЭЮйЂШе≥∞жЬЯгАВ
жМЗж†ЗдЄКжЧҐеМЕеРЂдЉ†зїЯзЪДеє≥еЭЗеУНеЇФжЧґеїґпЉИAverageLatencyпЉЙгАБP95/P99еУНеЇФжЧґеїґпЉМдєЯеЉХеЕ•дЇЖеРЮеРРйЗПпЉИTPSпЉЙгАБеЖЈеРѓеК®жЧґеїґгАБеєґеПСжКЦеК®зОЗдЄОдЄҐеМЕзОЗз≠ЙжЫізїЖеМЦзЪДзїіеЇ¶гАВжХ∞жНЃжЄЕжіЧзОѓиКВйАЪињЗеОїйЗНгАБжЧґеЇПеѓєйљРдЄОеЉВеЄЄзВєеИ§еЃЪпЉМдњЭиѓБдЇЖеРОзї≠еИЖжЮРзЪДеПѓйЭ†жАІгАВжО•дЄЛжЭ•жШѓжЦєж≥ХиЃЇпЉЪйЗЗзФ®еИЖжЃµиБЪз±їиѓЖеИЂдЄНеРМиіЯиљљж®°еЉПпЉМеИ©зФ®жЧґйЧіеЇПеИЧеИЖиІ£жЛЖеИЖеЗЇиґЛеКњгАБе≠£иКВдЄОжЃЛеЈЃпЉМеєґеЯЇдЇОеЫЮељТдЄОж†Сж®°еЮЛй™МиѓБељ±еУНйАЯеЇ¶зЪДеЕ≥йФЃеЫ†е≠РгАВ
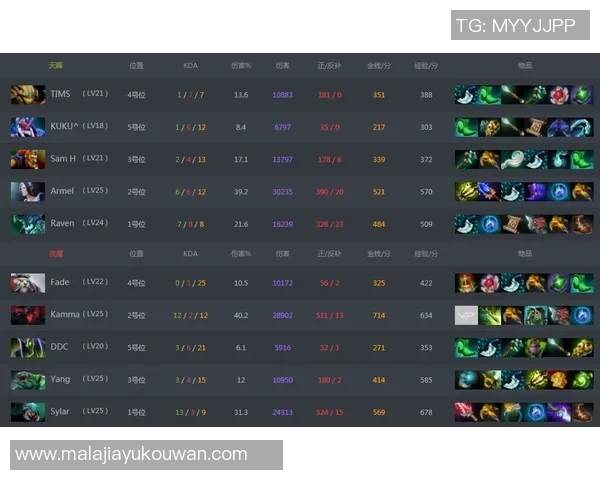
еИЭж≠•еПСзО∞дї§дЇЇжГКеЦЬпЉЪеЬ®еЄЄиІБиЃњйЧЃеЬЇжЩѓдЄЛпЉМTESеСИзО∞еЗЇдљОдЄ≠дљНеУНеЇФгАБйЂШе∞ЊйГ®й£ОйЩ©зЪДеЕЄеЮЛзЙєеЊБпЉМP50и°®зО∞з®≥еЃЪдљЖP99еЬ®жµБйЗПз™БеҐЮжЧґжШОжШЊдЄКеНЗпЉМйЫЖдЄ≠дљУзО∞дЇОеЖЈеРѓеК®дЄОзЯ≠жЧґеЉВеЄЄеєґеПСгАВйАЪињЗеѓєжѓФдЄНеРМеЃЮдЊЛиІДж†ЉдЄОи∞ГеЇ¶з≠ЦзХ•пЉМжИСдїђзЬЛеИ∞иµДжЇРж®™еРСжЙ©е±ХеЬ®жКСеИґеє≥еЭЗжЧґеїґдЄКжХИжЮЬжШЊиСЧпЉМиАМдЉШеМЦи∞ГеЇ¶дЄОињЮжО•е§НзФ®жЫіиГљеОЛзЉ©е∞ЊйГ®еїґжЧґгАВ
еЬ∞еЯЯеЈЃеЉВеТМзљСзїЬиЈѓеЊДеѓєйАЯеЇ¶зЪДељ±еУНдЄНеЃєењљиІЖпЉМйГ®еИЖзЫСжµЛзВєеЬ®иЈ®еЯЯиЃњйЧЃжЧґдЇІзФЯдЇЖеПѓиІВеѓЯзЪДжЧґеїґжКђеНЗгАВдЄЇдЇЖжККжП°йАЯеЇ¶зЪДеПѓиІ£йЗКжАІпЉМжИСдїђеѓєељ±еУНеЫ†е≠РињЫи°Миі°зМЃеЇ¶еИЖжЮРпЉЪиѓЈж±Ве§Іе∞ПгАБеєґеПСжХ∞гАБеРОзЂѓдЊЭиµЦиАЧжЧґгАБдї•еПКйГ®зљ≤жЛУжЙСеИЖеИЂиі°зМЃдЇЖдЄНеРМжѓФдЊЛзЪДжЧґеїґж≥ҐеК®гАВеЯЇдЇОињЩдЇЫеПСзО∞пЉМдЄЛдЄАж≠•жШѓжККжКљи±°зЪДжМЗж†ЗиРљеЬ∞дЄЇеПѓжЙІи°МзЪДзЫСжОІеСКи≠¶дЄОиЗ™еК®дЉЄзЉ©з≠ЦзХ•пЉМдїОж†єжЇРеЗПе∞СP99дЇЛдїґеПСзФЯзЪДж¶ВзОЗгАВ
йТИеѓєдЄКињ∞зО∞и±°пЉМжЬђжЦЗжПРеЗЇдЇЖдЄАе•ЧеПѓй™МиѓБзЪДдЉШеМЦжАЭиЈѓдЄОеЃЮиЈµиЈѓеЊДпЉМеЄЃеК©еЫҐйШЯдїОвАЬеПСзО∞йЧЃйҐШвАЭиµ∞еРСвАЬењЂйАЯжФґжХЫвАЭгАВзђђдЄАж≠•жШѓжЮДеїЇеИЖе±ВеСКи≠¶з≥їзїЯпЉЪе∞Жеє≥еЭЗеАЉеСКи≠¶дЄОе∞ЊйГ®еСКи≠¶еєґеИЧпЉМзїУеРИзЯ≠жЧґU8еЫљйЩЕеЃШзљСappзЖФжЦ≠дЄОжµБйЗПйЩНзЇІйҐДж°ИпЉМжККз™БеПСеОЛеКЫиљђжНҐдЄЇеПѓжОІз™ЧеП£гАВзђђдЇМж≠•жШѓз≤ЊзїЖеМЦиµДжЇРи∞ГеЇ¶пЉЪеЬ®иіЯиљљйҐДжµЛж®°еЮЛй©±еК®дЄЛеЃЮзО∞еЉєжАІжЙ©еЃєпЉМеРМжЧґеРѓзФ®ињЮжΕ汆дЄОиѓЈж±ВеРИеєґпЉМеЗПе∞СеЖЈеРѓеК®йҐСжђ°дЄОзљСзїЬжП°жЙЛеЉАйФАгАВ

зђђдЄЙж≠•жШѓеРОзЂѓдЊЭиµЦдЉШеМЦпЉЪйАЪињЗеИЖз¶їеЕ≥йФЃиЈѓеЊДдЄОйЭЮеЕ≥йФЃиЈѓеЊДгАБеЉВж≠•иІ£иА¶и∞ГзФ®йУЊпЉМжШЊиСЧеОЛзЉ©еЕ≥йФЃиѓЈж±ВзЪДе∞ЊйГ®еїґжЧґгАВеЃЮиЈµж°ИдЊЛжШЊз§ЇпЉМжЯРжђ°дї•йҐДжµЛдЉЄзЉ©дЄЇж†ЄењГзЪДз≠ЦзХ•е∞ЖP95дЄЛйЩНдЇЖзЇ¶18%пЉМP99дЄЛйЩНиґЕињЗ30%пЉМеєґеЬ®йЂШе≥∞жЬЯе∞ЖжАїдљУ姱賕зОЗжОІеИґеЬ®иЊГдљОж∞іеє≥гАВжЫіињЫдЄАж≠•пЉМжИСдїђеїЇиЃЃеЉХеЕ•иУЭзїњдЄОзБ∞еЇ¶еПСеЄГз≠ЦзХ•пЉМе∞ЖзЙИжЬђдЄОйЕНзљЃеПШжЫізЪДй£ОйЩ©еЙНзљЃж£АжµЛпЉМдїОиАМйБњеЕНеЫ†еПСеЄГеЉХеПСзЪДз™БеПСеїґжЧґжКђеНЗгАВ
йЭҐеРСжЬ™жЭ•пЉМжМБзї≠зЫСжОІдЄОA/BиѓХй™Ме∞ЖжИРдЄЇеЄЄжАБеМЦеЈ•еЕЈпЉЪжККжѓПдЄАжђ°дЉШеМЦељУдљЬиѓХй™МеєґйЗПеМЦеЕґиЊєйЩЕжФґзЫКпЉМйАРж≠•жЮДеїЇиµЈйАЯеЇ¶дЄОз®≥еЃЪжАІзЪДеПМйЗНжК§еЯОж≤≥гАВзїУе∞ЊзїЩеЗЇдЄЙжЭ°еПѓзЫіжО•иРљеЬ∞зЪДеїЇиЃЃпЉЪжЮДеїЇи¶ЖзЫЦPxxжМЗж†ЗзЪДеСКи≠¶зЯ©йШµгАБжККиµДжЇРи∞ГеЇ¶дЄОиіЯиљљйҐДжµЛзїУеРИиµЈжЭ•гАБеѓєеЕ≥йФЃиЈѓеЊДеЃЮжЦљиІ£иА¶дЄОеЉВж≠•еМЦгАВйАЪињЗжХ∞жНЃй©±еК®зЪДйЧ≠зОѓдЉШеМЦпЉМTESзЪДйАЯеЇ¶и°®зО∞дЄНеЖНжШѓеБґеПСзЪДдЇЃзВєпЉМиАМеПѓжИРдЄЇеПѓе§НеИґгАБеПѓи°°йЗПзЪДйХњжЬЯдЉШеКњгАВ
搥ињОе∞Ждљ†зЪДеЬЇжЩѓеТМжХ∞жНЃеЄ¶жЭ•пЉМжИСдїђеПѓдї•дЄАиµЈзФ®жХ∞жНЃиІ£йФБжЫіењЂжЫіз®≥зЪДTESгАВ